

Machine Learning Operations (MLOps): Um Guia para a Construção de Arquiteturas de Software Otimizadas
Machine Learning Operations (MLOps) representa uma convergência entre o desenvolvimento de produtos de trabalho de Machine Learning (ou Aprendizado de Máquina) - em geral, modelos - e as operações de TI, como uma resposta às complexidades emergentes na era dos dados.
Enquanto o DevOps se concentra na entrega contínua de software, o MLOps foca especificamente na automação e na eficiência dos pipelines de ML.
O problema abordado pelo MLOps é a lacuna frequentemente encontrada entre a teoria do ML e sua aplicação prática. Muitos modelos falham ao transitar do laboratório para o mundo real devido à falta de consideração por aspectos operacionais.
A motivação para o MLOps surge da necessidade de agilizar o ciclo de vida dos modelos de ML, desde a concepção até a produção, garantindo que sejam não apenas tecnicamente viáveis, mas também prontamente implantáveis e sustentáveis em ambientes de produção.
Neste artigo vamos tentar explorar todos os recursos que ajudam a compreender não apenas o ‘como’, mas o ‘porquê’ do MLOps estar ganhando muitos adeptos e viabilizando a criação de novos negócios intensivos em Engenharia de Software e fornecendo um entendimento mais profundo e crítico das práticas e desafios envolvidos na integração de ML com operações de TI.
Ciclo de Vida do Modelo de Machine Learning
O ciclo de vida de um modelo de Machine Learning é um processo complexo e multifacetado, essencial para entender no contexto de MLOps. Esta seção busca desvendar as etapas - em um alto nívl de abstração - do ciclo de vida de um modelo de Machine Learning, enfatizando a importância de cada fase no contexto das operações de Machine Learning. As subseções detalham aspectos específicos, incluindo coleta de dados, treinamento, avaliação, implantação e monitoramento, cada uma crucial para o sucesso de um projeto de Machine Learning.
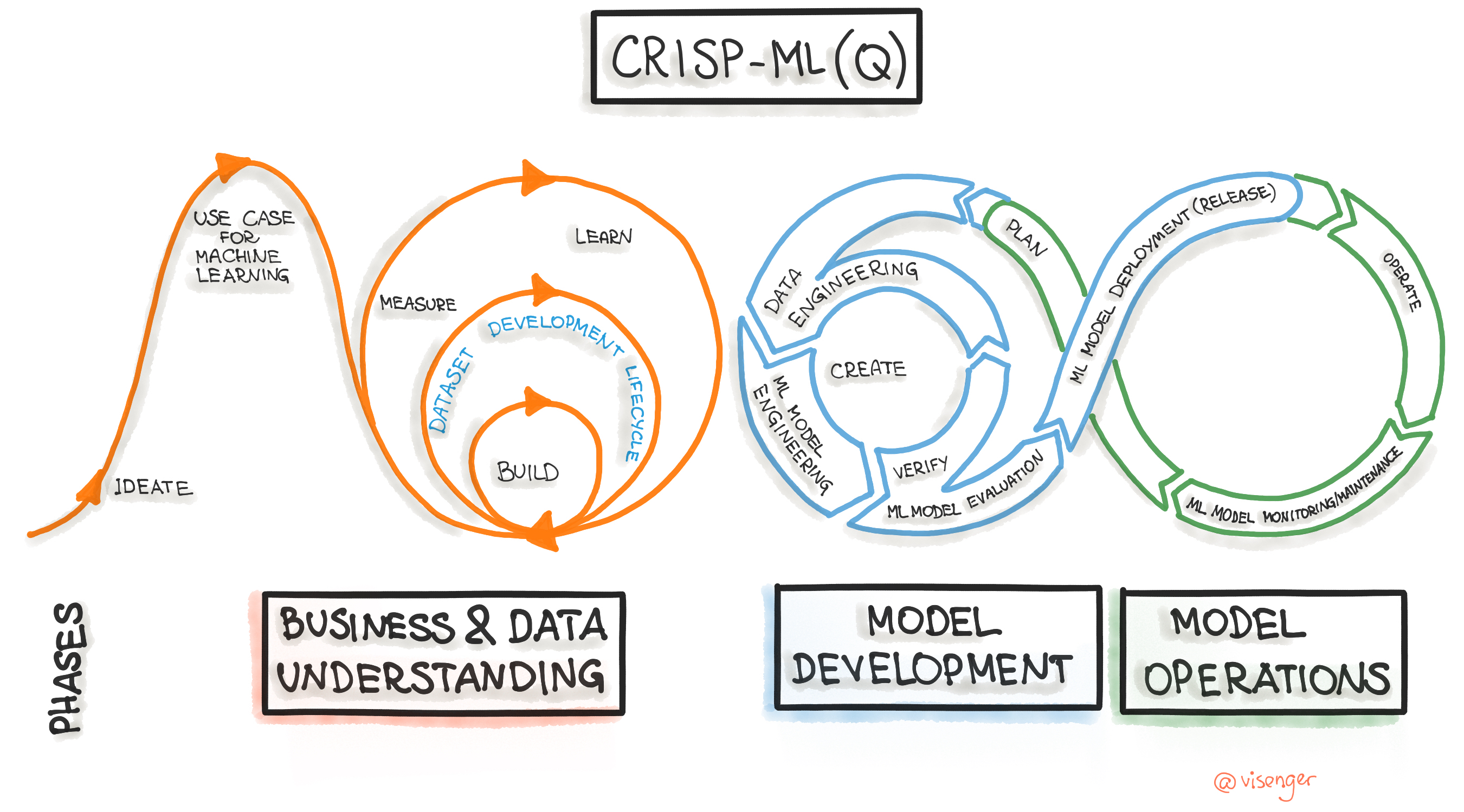
Figura 1: Machine Learning Development Life Cycle Process.
Para quem quiser um olhar mais profundo, indico o artigo CRISP-ML(Q). The ML Lifecycle Process).
Coleta de Dados e Preparação
Dentro do ciclo de vida do modelo de Machine Learning, como discutido na seção anterior, a coleta de dados e sua preparação são os primeiros passos nsta jornada. Esta subseção tem por objetivo se aprofundar na importância e nas metodologias da coleta e preparação de dados, estabelecendo como essas atividades colaboram para o sucesso subsequente das fases de treinamento, avaliação e implantação do modelo.
A coleta de dados é mais do que simplesmente agrupar informações. Ela envolve a identificação e o acesso a fontes de dados relevantes e representativas. Esses dados podem vir de diversas fontes, como bancos de dados internos, APIs públicas, dispositivos IoT e mídias sociais. O desafio aqui é garantir que os dados sejam não apenas abundantes, mas também de alta qualidade e relevantes para o problema específico de Machine Learning a ser resolvido. Conforme já discutimos antes, a qualidade dos dados coletados influencia diretamente a eficácia dos modelos de Machine Learning.
Uma vez coletados, os dados precisam ser preparados, o que inclui tarefas de limpeza, normalização, transformação e enriquecimento. A limpeza de dados envolve a remoção de inconsistências, dados ausentes ou irrelevantes. A normalização ajusta diferentes escalas de dados para um padrão comum, essencial para algoritmos de Machine Learning sensíveis a variações de escala.
A transformação de dados pode incluir a conversão de formatos não estruturados para estruturados, essencial em ambientes de big data. Já o enriquecimento de dados, muitas vezes esquecido, pode incluir a adição de informações contextuais que aumentam a capacidade do modelo de Machine Learning de fazer previsões com mais acurácia e precisão.
Ainda assim, não podemos deixar de destacar alguns Desafios e Soluções na Coleta de Dados.
A partir do que já foi dito sobre a importânca da qualidade dos dados, já podemos destacar que um desafio significativo na coleta de dados é garantir que eles sejam representativos da população ou do fenômeno que o modelo pretende analisar. Isso é crucial para evitar viéses no modelo de Machine Learning. A diversidade de dados é, portanto, uma preocupação principal, como destacado em “Data Science for Business” por Provost e Fawcett.
Outro desafio é a gestão de grandes volumes de dados, especialmente em formatos variados. A utilização de tecnologias de big data e sistemas de gerenciamento de banco de dados eficientes são soluções práticas para este problema.
A partir do que discutimos anteriormemnte, fica claro que a integração da coleta e preparação de dados no fluxo de trabalho de MLOps é vital. Isso garante a criação de um pipeline de dados eficiente e automatizado, essencial para o desenvolvimento ágil de modelos de Machine Learning. Falaremos mais sobre isso na seção de “Automatização e Orquestração de Workflows” deste artigo, em especial sobre como a eficácia do pipeline de dados influencia diretamente a velocidade e a qualidade do desenvolvimento e implantação de modelos de Machine Learning.
Treinamento e Validação do Modelo
Após a fase de coleta e preparação de dados, discutida anteriormente, o ciclo de vida do modelo de Machine Learning progride para o treinamento e validação do modelo. Nesta subseção vamos abordar os principais aspectos, ressaltando a importância do treinamento eficiente e da validação rigorosa para garantir a criação de modelos de Machine Learning precisos e confiáveis.
O treinamento de modelos é o processo de alimentar dados ao algoritmo de Machine Learning para que ele aprenda padrões e características. A qualidade do treinamento determina a eficácia do modelo em realizar previsões ou classificações. Uma técnica de treinamento bem-sucedida considera não apenas a quantidade, mas também a qualidade e a representatividade dos dados de treinamento. A escolha do algoritmo e a configuração dos parâmetros são cruciais para um treinamento eficaz.
Após o treinamento, a validação do modelo é essencial para testar sua eficácia em dados não vistos anteriormente. Esta etapa tem por propósito verificar se o modelo é generalizável para diferentes conjuntos de dados e situações. A validação pode ser realizada através de técnicas como validação cruzada, onde o conjunto de dados é dividido em várias partes para testar a robustez do modelo. Algmas publicações (01, 02, 03, 04, 05) ressaltam a importância da validação na prevenção de problemas como overfitting, onde o modelo se torna excessivamente ajustado aos dados de treinamento.
Já falamos, algumas muitas vezes ao longo dessa jornada, que um dos principais desafios no treinamento de modelos de Machine Learning é garantir que os dados sejam representativos e livres de viés (spoiler: vamos falar algumas vezes mais). Como discutido na seção de “Coleta de Dados e Preparação”, a qualidade dos dados tem um impacto direto na eficácia do modelo. Além disso, o ajuste de hiperparâmetros e a escolha de algoritmos adequados são essenciais para otimizar o desempenho do modelo.
Na validação, o desafio é garantir que o modelo não apenas se apresente bem nos dados de teste, mas também mantenha sua precisão em situações do mundo real. A aplicação de técnicas de validação adequadas é fundamental para este processo.
Avaliação e Ajustes de Modelo
Continuando a jornada pelo ciclo de vida do modelo de Machine Learning, após a fase de treinamento e validação, é essencial focar na avaliação e nos ajustes do modelo. Esta subseção explora a importância dessa etapa e as melhores práticas para garantir que os modelos de Machine Learning sejam não apenas precisos, mas também aplicáveis e eficientes em ambientes de produção.
Após treinar e validar um modelo, a avaliação tem por objetivo compreender sua performance em cenários práticos. Essa avaliação envolve a análise de várias métricas de desempenho, como precisão, recall, F1-score e área sob a curva ROC (Receiver Operating Characteristic). Essas métricas fornecem insights sobre a eficácia do modelo em termos de precisão de previsões e capacidade de generalização.
Com base nos resultados da avaliação, o modelo pode requerer ajustes para melhorar seu desempenho. Isso pode incluir a otimização de hiperparâmetros, a revisão de características dos dados ou mesmo a alteração do algoritmo de Machine Learning. Este processo de ajuste é iterativo e necessita de uma abordagem sistemática para identificar as áreas de melhoria. Um desafio comum, como destacado na seção “Treinamento e Validação do Modelo”, é evitar o overfitting, onde o modelo performa bem nos dados de treinamento, mas falha em generalizar para novos dados.
Um dos desafios na avaliação de modelos de Machine Learning é garantir que o modelo seja robusto em diferentes contextos e conjuntos de dados. Além disso, os ajustes necessários podem ser extensos e complexos, exigindo uma compreensão profunda tanto dos dados quanto do domínio de aplicação. A necessidade de equilibrar a precisão do modelo com a eficiência computacional e a facilidade de implantação também é um aspecto importante a ser considerado.
Implantação do Modelo
Após a fase de avaliação e ajustes, o ciclo de vida do modelo de Machine Learning avança para a implantação do modelo.
A implantação é o processo de integrar um modelo de ML treinado e testado no ambiente de produção onde ele será utilizado. É aqui que o modelo começa a entregar valor prático, aplicando seu aprendizado a dados do mundo real. A implantação eficaz exige uma combinação de conhecimento técnico e entendimento do ambiente operacional.
Um dos maiores desafios na implantação é garantir a compatibilidade do modelo com a infraestrutura existente. Isso envolve considerações sobre a escalabilidade, o desempenho e a segurança do modelo em um ambiente de produção. Além disso, como indicado na seção de “Treinamento e Validação do Modelo”, é essencial garantir que o modelo mantenha sua precisão e eficácia quando exposto a dados novos e potencialmente variáveis.
Para uma implantação bem-sucedida, é fundamental adotar uma abordagem sistemática que considere todos os aspectos do ecossistema de produção. Isso inclui:
- Testes Rigorosos: Antes da implantação, o modelo deve passar por uma série de testes para garantir que funciona conforme esperado em diferentes cenários.
- Monitoramento Contínuo: Após a implantação, é vital monitorar o desempenho do modelo continuamente para detectar e corrigir qualquer deriva ou degradação no tempo.
- Integração com Sistemas Existentes: A implantação deve ser feita de forma que o modelo se integre perfeitamente com os sistemas e processos já existentes.
A implantação eficaz de modelos em MLOps é o que pode transformar teorias e conceitos em soluções práticas que impactam positivamente organizações e indivíduos.
Monitoramento e Manutenção
Após a implantação do modelo, entramos na fase final, contínua, do ciclo de vida do modelo de Machine Learning: o monitoramento e a manutenção.
Uma vez que um modelo está em produção, precisamos monitorar continuamente seu desempenho. Esta vigilância ajuda a identificar problemas como a deriva de modelo (do inglês, model drift) - uma mudança gradual na eficácia do modelo devido a alterações nos padrões subjacentes dos dados de entrada. O monitoramento eficaz garante que os modelos mantenham sua precisão e relevância. A deriva de modelo pode ser particularmente insidiosa, pois pode ocorrer lentamente e passar despercebida sem sistemas de monitoramento adequados.
Além do monitoramento, a manutenção regular dos modelos é essencial. Isso inclui a recalibração ou o re-treinamento do modelo com novos dados para adaptá-lo às mudanças nas tendências ou comportamentos. Como mencionado na seção de “Avaliação e Ajustes de Modelo”, a capacidade de ajustar modelos rapidamente é crucial para manter sua eficácia. Isso pode exigir uma abordagem proativa, onde os modelos são periodicamente avaliados e ajustados, mesmo na ausência de sinais óbvios de degradação.
O monitoramento e a manutenção de modelos de Machine Learning em ambientes de produção apresentam desafios únicos, tais como, a identificação de métricas apropriadas para o monitoramento, a determinação do momento certo para re-treinar os modelos, e a gestão de recursos para a manutenção contínua. Além disso, como indicado na seção “Implantação do Modelo”, a integração de modelos atualizados em sistemas de produção existentes pode ser complexa.
Gestão de Dados em MLOps
Esta seção aborda detalhadamente a importância, os desafios e as estratégias associadas à gestão de dados em ambientes de Machine Learning. A capacidade de gerir dados eficientemente não só influencia diretamente a qualidade dos modelos de Machine Learning, mas também determina a eficácia global das operações de MLOps.
Importância da Qualidade e Governança dos Dados
No contexto deste artigo, a gestão eficaz de dados e a governança dos dados merecem atenção especial, pois esses aspectos fundamentam 0 alicerce do sucesso em Machine Learning que é a Qualidade dos Dados.
Dados de alta qualidade são essenciais para modelos de Machine Learning confiáveis. Como será discutido na próxima seção sobre “Gerenciamento Eficiente de Dados em Larga Escala”, sem dados precisos, limpos e relevantes, até mesmo os algoritmos mais avançados podem falhar em produzir resultados úteis. A qualidade dos dados impacta diretamente em aspectos como a acurácia da previsão, a generalização do modelo e a velocidade do treinamento.
Parâmetros críticos que definem a qualidade dos dados incluem sua completude, precisão, consistência e atualidade. Garantir a integridade dos dados envolve a verificação de campos ausentes, a correção de erros e a eliminação de duplicatas. Além disso, a relevância dos dados para o contexto específico do problema de Machine Learning é igualmente importante.
Para podermos assegurar Conformidade e Ética, precisamos de Governança dos Dados.
A governança dos dados em MLOps não é apenas uma questão de conformidade regulatória; ela também aborda a ética e a transparência no uso de dados. Isso se torna ainda mais crítico à medida que aumentam as preocupações com a privacidade dos dados e os direitos dos indivíduos.
A governança eficaz dos dados inclui a gestão do acesso aos dados, o controle de versões, a auditoria de uso e a conformidade com leis como o GDPR (Regulamento Geral sobre a Proteção de Dados) na Europa. Ela também envolve a implementação de políticas para a manipulação ética de dados, especialmente quando lidamos com dados sensíveis ou pessoais.
Os desafios na manutenção da qualidade e governança dos dados são muitos, incluindo a integração de fontes de dados heterogêneas, a manutenção da qualidade dos dados em larga escala e a adaptação às mudanças na legislação de privacidade de dados.
Estratégias para superar esses desafios incluem o uso de tecnologias automatizadas para a limpeza e o processamento de dados, bem como a adoção de um quadro de governança de dados robusto, que esteja alinhado com as melhores práticas e regulamentos atuais.
A qualidade e a governança dos dados em MLOps são mais do que procedimentos de gestão; elas são as fundações sobre as quais modelos de Machine Learning confiáveis e éticos são construídos, garantindo a sustentabilidade e a eficácia a longo prazo das suas operações.
Gerenciamento Eficiente de Dados em Larga Escala
No âmbito de dessa nossa jornada em MLOps, a eficácia das operações está intrinsecamente ligada ao gerenciamento eficiente de dados em larga escala. Esta subseção se aprofunda nesse aspecto, expandindo sobre a importância de estratégias robustas de gestão de dados e as tecnologias envolvidas, especialmente considerando os desafios apresentados na subseção anterior sobre “Importância da Qualidade e Governança dos Dados”.
Em ambientes de MLOps, gerenciar grandes volumes de dados exige soluções de armazenamento que sejam escaláveis, seguras e eficientes. O uso de data lakes e data warehouses é fundamental para armazenar dados de diferentes tipos e estruturas. Soluções de armazenamento em nuvem, como AWS S3 ou Google Cloud Storage, oferecem escalabilidade e flexibilidade, permitindo às organizações ajustar recursos de armazenamento conforme a necessidade.
O versionamento de dados é crucial para manter um histórico detalhado das alterações nos dados. Ferramentas como DVC (Data Version Control) ou Git-LFS (Large File Storage) são essenciais para rastrear modificações, facilitando a reprodução de experimentos e modelos de Machine Learning, uma prática essencial conforme discutido na seção “Avaliação e Ajustes de Modelo”.
A limpeza de dados, que envolve corrigir ou remover dados incorretos, incompletos ou irrelevantes, tem por objetivo garantir a qualidade dos dados. Processos automatizados de limpeza de dados são fundamentais em ambientes de big data, onde o volume de dados torna a limpeza manual impraticável.
Após a limpeza, os dados precisam ser transformados e normalizados para prepará-los para análise. Este processo pode incluir a codificação de variáveis categóricas, a normalização de escalas e a transformação de dados não estruturados em formatos estruturados, um aspecto discutido na seção “Treinamento e Validação do Modelo”.
Um desafio significativo é integrar dados de fontes heterogêneas, mantendo a consistência e qualidade. Ferramentas de ETL (Extract, Transform, Load) e soluções de middleware de integração de dados podem ajudar a superar esses desafios. Além disso, a escalabilidade do armazenamento de dados, especialmente em ambientes de nuvem, é crucial para lidar com o crescimento exponencial dos volumes de dados.
Garantir que os dados sejam atualizados e relevantes é outro desafio. Técnicas de streaming de dados e pipelines de dados em tempo real são essenciais para manter os dados sincronizados com as fontes.
Desafios na Gestão de Dados
A gestão de dados representa um conjunto de desafios complexos e multifacetados. Esta subseção, ampliando a discussão iniciada nas seções anteriores sobre a importância da qualidade e governança dos dados e o gerenciamento eficiente de dados em larga escala, se concentra nos desafios específicos enfrentados na gestão de dados dentro do MLOps.
Um dos principais desafios em MLOps é integrar dados de diversas fontes, cada uma com seus próprios formatos, padrões e qualidade. Como abordado na subseção “Gerenciamento Eficiente de Dados em Larga Escala”, a harmonização desses dados heterogêneos é crucial para garantir que os modelos de Machine Learning sejam treinados com informações completas e representativas.
O armazenamento e processamento de grandes volumes de dados impõem desafios significativos em termos de escalabilidade. Soluções de armazenamento devem ser capazes de se adaptar dinamicamente às necessidades em constante mudança, um aspecto crucial discutido anteriormente na mesma subseção.
A qualidade dos dados é primordial para o sucesso de operações de MLOps. Dados incorretos, incompletos ou desatualizados podem levar a insights errôneos e a modelos de ML ineficazes. Como mencionado na subseção “Importância da Qualidade e Governança dos Dados”, a implementação de processos de limpeza e verificação de dados é fundamental, mas pode ser desafiadora, especialmente em larga escala.
Com o aumento das preocupações com a privacidade dos dados e a crescente regulamentação global, garantir a conformidade é um desafio contínuo. O GDPR na Europa, LGPD no Brasil e outras legislações semelhantes exigem que as organizações gerenciem dados de maneira responsável e transparente.
Manter os dados atualizados e relevantes é crucial, especialmente em ambientes dinâmicos onde os padrões de dados podem mudar rapidamente. Isso requer não apenas armazenamento eficiente, mas também sistemas de atualização contínua e monitoramento.
Tentamos ressaltar que enfrentar os desafios na gestão de dados em MLOps é crucial para o desenvolvimento e implementação bem-sucedidos de modelos de Machine Learning. Compreender e superar esses desafios permite não apenas construir modelos mais precisos e confiáveis, mas também assegura a sustentabilidade e a eficácia a longo prazo das operações de MLOps.
Por conta do que discutimpos aqui, a gestão eficaz de dados se apresenta como um pilar fundamental em MLOps, impactando diretamente a qualidade e a eficácia dos modelos de Machine Learning.
Automatização e Orquestração de Workflows
Continuando a nossa jornada, vamos agora discutir os aspectos relacionados a Automatização e Orquestração de Workflows. Nesta seção, vamos expandir e aprofundar a discussão sobre como a automatização e a orquestração de workflows são fundamentais para a eficiência e eficácia das operações de MLOps, abordando tanto os aspectos técnicos quanto os desafios práticos.
Fundamentos da Automatização em MLOps
A automatização em MLOps emergiu como uma faceta crucial, conectando-se diretamente com a discussão anterior sobre a importância da gestão eficiente de dados e preparando o terreno para a subsequente exploração da orquestração de workflows.
Ela é fundamental para alcançar a eficiência operacional e a escalabilidade necessária para lidar com grandes volumes de dados e modelos complexos. Justamente porque ela permite a execução de tarefas repetitivas, como processamento e limpeza de dados, de maneira mais rápida e menos propensa a erros do que os métodos manuais.
Ao automatizar tarefas rotineiras, os cientistas de dados e engenheiros de Machine Learning podem se concentrar em atividades mais inovadoras, como a experimentação com novos algoritmos e a melhoria da qualidade dos modelos. Isso resulta em um ciclo de desenvolvimento mais rápido e uma maior capacidade de inovação.
Ferramentas de CI/CD, como Jenkins e CircleCI, são essenciais para automatizar o teste e a implantação de modelos de Machine Learning. Elas permitem uma integração contínua de mudanças no código e uma entrega contínua de atualizações de modelos, garantindo que novas versões sejam confiáveis e estejam prontas para produção.
Tecnologias como Docker e Kubernetes facilitam a automação ao gerenciar containers, que são essenciais para a criação de ambientes consistentes e isolados para treinamento e implantação de modelos. Isso assegura que os modelos sejam executados da mesma maneira em diferentes ambientes, desde o desenvolvimento até a produção.
Um dos principais desafios na automatização em MLOps é encontrar o equilíbrio certo entre processos automatizados e a necessidade de flexibilidade e ajuste manual. É muito importante garantir que os sistemas automatizados não se tornem tão rígidos a ponto de impedir ajustes rápidos e personalizações necessárias.
Além disso, a garantia de qualidade nos processos automatizados é o que vai garantir um produto ficaz e eficiente. Isso inclui a implementação de sistemas de monitoramento robustos para detectar e responder a falhas ou ineficiências nos workflows automatizados.
Orquestração de Workflows em MLOps
Nesta subseção vamos nos aprofundar nos aspectos da orquestração de workflows, enfatizando como ela facilita a coordenação eficiente de múltiplas tarefas e processos dentro do ciclo de vida do Machine Learning.
A orquestração de workflows é crucial para gerenciar a complexidade inerente aos processos de Machine Learning. Ela envolve a coordenação de várias etapas, desde a preparação de dados até o treinamento, validação e implantação de modelos, assegurando que cada etapa seja executada na sequência e configuração corretas. Isso é essencial para manter a integridade do processo de Machine Learning, garantindo resultados confiáveis e replicáveis.
A orquestração também facilita a colaboração entre equipes de dados, engenheiros de software e stakeholders do negócio. Ela permite que diferentes partes do processo de Machine Learning sejam integradas de maneira harmoniosa, proporcionando transparência e eficiência operacional.
Ferramentas como Apache Airflow e Kubeflow são amplamente utilizadas para a orquestração de workflows em MLOps. O Apache Airflow permite definir, programar e monitorar workflows complexos, enquanto o Kubeflow é projetado especificamente para orquestrar pipelines de Machine Learning em ambientes Kubernetes.
Estas ferramentas de orquestração geralmente são integradas com outras ferramentas de automatização e sistemas de monitoramento, proporcionando uma visão abrangente e controle sobre os pipelines de ML. Isso garante que todas as etapas do processo sejam executadas de forma eficiente e os problemas possam ser identificados e resolvidos rapidamente.
Um dos principais desafios na orquestração de workflows em MLOps é gerenciar a complexidade sem sacrificar a flexibilidade. Os pipelines de Machine Learning muitas vezes necessitam de ajustes e modificações rápidas em resposta a novos dados ou requisitos de negócios.
Outro desafio é garantir a qualidade e a escalabilidade dos workflows orquestrados. À medida que os projetos de Machine Learning aumentam em escala, a orquestração deve ser capaz de lidar com a crescente carga de trabalho e complexidade, mantendo a eficiência e a confiabilidade.
A orquestração de workflows em MLOps é o que contribui para a eficiência e eficácia dos processos de Machine Learning. Ela permite que as organizações gerenciem complexidades, coordenem tarefas diversas e mantenham a integridade e a qualidade dos seus projetos de Machine Learning. Entender e aplicar efetivamente as práticas de orquestração em MLOps é fundamental para garantir que os esforços de Machine Learning sejam bem-sucedidos e alinhados com os objetivos estratégicos do negócio.
Desafios na Automatização e Orquestração
A automatização e orquestração de workflows atuam para otimizar as operações de Machine Learning. No entanto, esses processos trazem consigo uma série de desafios que são críticos para o sucesso dos projetos. Esta subseção, seguindo a discussão sobre os fundamentos e a importância da automatização e orquestração em MLOps, foca nos desafios associados e em como eles podem ser abordados.
A complexidade dos workflows de Machine Learning, que inclui desde a coleta de dados até a implantação de modelos, é um dos maiores desafios. Garantir que cada etapa seja executada corretamente e na ordem certa requer uma coordenação meticulosa.
Ferramentas avançadas de orquestração, como Apache Airflow e Kubeflow, podem ajudar a gerenciar essa complexidade, mas exigem conhecimento técnico especializado para sua configuração e manutenção.
Outro desafio significativo é encontrar o equilíbrio entre a flexibilidade necessária para adaptar-se às necessidades específicas do projeto e a padronização essencial para a eficiência. Workflows muito rígidos podem limitar a inovação, enquanto sistemas excessivamente flexíveis podem levar a inconsistências e dificuldades na manutenção.
Adotar práticas de desenvolvimento ágil e integrar feedbacks contínuos das equipes de Machine Learning e stakeholders do negócio pode ajudar a manter esse equilíbrio.
A integração eficaz dos workflows de MLOps com sistemas de TI e de negócios já existentes é desafiadora. Isso inclui garantir que os dados fluam sem problemas entre diferentes sistemas e que os modelos de Machine Learning sejam facilmente integráveis em ambientes de produção existentes.
Usar APIs bem projetadas e adotar padrões de indústria pode facilitar essa integração, tornando os sistemas de MLOps mais compatíveis com a infraestrutura existente.
Os desafios na automatização e orquestração em MLOps são numerosos e variados, mas com uma abordagem cuidadosa e o uso de ferramentas e estratégias adequadas, podem ser superados, levando a operações de ML mais eficientes, eficazes e alinhadas com os objetivos de negócios.
Casos de Uso e Aplicações Práticas
Agora, exploraremos como a automatização e orquestração de workflows em MLOps são aplicadas no mundo real, expandindo a discussão anterior sobre seus fundamentos e desafios. Esta subseção foca em casos de uso concretos e aplicações práticas, demonstrando a relevância e o impacto dessas práticas em diversos setores.
Aplicações no Setor de Saúde: Diagnóstico e Prognóstico Assistido por Machine Learning e Pesquisa e Desenvolvimento de Medicamentos.
No setor de saúde, a automatização e orquestração em MLOps dãosuporte à análise de grandes volumes de dados de saúde, como imagens médicas e registros eletrônicos de saúde. Por exemplo, modelos de Machine Learning automatizados são utilizados para detectar padrões em imagens de ressonância magnética, auxiliando no diagnóstico precoce de doenças como o câncer.
A orquestração de workflows também é fundamental na pesquisa e desenvolvimento de novos medicamentos. Através da análise automatizada de dados bioquímicos, os modelos de Machine Learning podem identificar compostos promissores para testes clínicos, acelerando o processo de descoberta de medicamentos.
Aplicações no Setor Financeiro: Detecção de Fraude e Análise de Risco de Crédito.
No setor financeiro, a automatização em MLOps é usada para detectar padrões de transações fraudulentas. Sistemas de detecção de fraude utilizam modelos de Machine Learning que são constantemente atualizados e aprimorados através de processos automatizados, aumentando a eficiência e precisão na identificação de atividades suspeitas.
A orquestração de workflows permite a análise automatizada de dados de crédito para avaliar o risco de empréstimos. Modelos de Machine Learning analisam o histórico financeiro dos solicitantes e preveem a probabilidade de inadimplência, auxiliando na tomada de decisões de crédito.
Aplicações no Setor de Varejo: Personalização de Experiência do Cliente e Otimização de Cadeia de Suprimentos.
No varejo, a automatização em MLOps é empregada para personalizar a experiência de compra. Algoritmos de recomendação analisam o comportamento de compra dos clientes e automatizam a geração de recomendações personalizadas, aumentando a satisfação do cliente e as vendas.
A orquestração eficiente de workflows facilita a otimização da cadeia de suprimentos. Modelos de Machine Learning prevêem a demanda futura e automatizam a gestão de estoque, melhorando a eficiência logística e reduzindo custos.
Aplicações em Setores Diversificados: Previsão Meteorológica e Manutenção Preditiva em Manufatura.
Na meteorologia, modelos de Machine Learning automatizados são usados para prever condições climáticas. A orquestração de dados de múltiplas fontes, como satélites e estações meteorológicas, permite análises mais precisas e previsões de curto e longo prazo.
Na manufatura, a manutenção preditiva usa a automatização em MLOps para prever falhas em equipamentos. Sensores coletam dados operacionais que são analisados por modelos de Machine Learning, permitindo manutenções preventivas e reduzindo o tempo de inatividade.
As aplicações práticas da automatização e orquestração em MLOps são vastas e impactam significativamente diversos setores. Essas aplicações práticas ilustram como a automatização e orquestração em MLOps não são apenas conceitos teóricos, mas ferramentas poderosas que estão moldando o futuro de inúmeras indústrias, tornando os processos mais eficientes, precisos e inovadores.
Implantação e Monitoramento de Modelos
Nesta seção vamos discutir as estratégias, desafios e melhores práticas para a implantação eficaz de modelos de Machine Learning e seu monitoramento contínuo, garantindo que permaneçam eficientes e relevantes em ambientes de produção dinâmicos.
Estratégias para Implantação Eficaz de Modelos de Machine Learning
Ao quê devemos estar atentos para a Preparação para Implantação?
Antes da implantação, é crucial que o modelo de Machine Learning passe por uma avaliação rigorosa. Isso inclui testes de precisão, avaliação de desempenho e verificação da generalização do modelo para diferentes conjuntos de dados. Esta etapa assegura que o modelo está pronto para enfrentar cenários do mundo real.
A escolha do ambiente de implantação, seja em nuvem ou on-premises, depende de fatores como custo, escalabilidade, segurança e conformidade regulatória. A preparação do ambiente inclui a configuração de servidores, a alocação de recursos e a garantia de que o modelo está integrado com os sistemas existentes.
Estratégias como implantação canary ou blue-green deployment permitem uma transição suave para o novo modelo. Elas envolvem a implantação gradual do modelo em um ambiente de produção, permitindo testar e ajustar o modelo em condições reais antes de um lançamento completo.
O uso de contêineres e microserviços facilita a implantação e a gestão de modelos de Machine Learning. Estas abordagens proporcionam isolamento, facilitam a escalabilidade e melhoram a eficiência na gestão de diferentes versões do modelo.
Um dos maiores desafios é integrar o modelo de ML com sistemas e processos de negócios existentes. Soluções de API bem projetadas e o uso de padrões de indústria podem facilitar essa integração.
Garantir que o modelo possa ser escalado para lidar com grandes volumes de dados e manter um desempenho estável sob carga é essencial. Técnicas como auto-scaling e balanceamento de carga são fundamentais para lidar com essas questões.
E uma vez implantado, precisamos ter um Monitoramento Pós-Implantação (falaremos mais, em mais detalhes, a seguir). Isso inclui a identificação de deriva de modelo ou mudanças nos padrões de dados que possam afetar a eficácia do modelo.
Ferramentas como Prometheus, Grafana e outras soluções de monitoramento de Machine Learning podem ser usadas para rastrear o desempenho do modelo e alertar sobre quaisquer questões que surjam.
A implantação eficaz de modelos de Machine Learning em MLOps é um processo complexo, mas essencial para garantir que os esforços de desenvolvimento se traduzam em impacto real e mensurável.
Ao detalharmos as estratégias para uma implantação eficaz de modelos de ML em MLOps, reforçamos a importância de uma abordagem cuidadosamente planejada e executada, com ênfase na preparação rigorosa, estratégias de implantação flexíveis e monitoramento contínuo, garantindo que os modelos de Machine Learning ofereçam valor contínuo e sejam sustentáveis no ambiente de produção.
Monitoramento Contínuo de Modelos
Conforme adiantamos anteriormente, monitoramento contínuo é essencial para assegurar que os modelos de Machine Learning continuem a operar com a eficácia esperada. Mudanças nos padrões de dados, conhecidas como deriva de dados, podem afetar significativamente a performance dos modelos. Por isso, é crucial monitorar e ajustar os modelos continuamente.
Modelos de Machine Learning podem se tornar obsoletos rapidamente devido a mudanças nas condições do mercado, preferências dos clientes ou outras dinâmicas externas. O monitoramento contínuo ajuda a identificar tais mudanças e a adaptar os modelos conforme necessário.
Técnicas como o monitoramento em tempo real, alertas automatizados e dashboards interativos são fundamentais. Além disso, a aplicação de técnicas de A/B e shadow mode permite testar novas versões dos modelos em paralelo com as versões existentes, minimizando riscos.
Um dos principais desafios no monitoramento de modelos de Machine Learning é gerenciar e analisar grandes volumes de dados de desempenho. Isso requer uma infraestrutura robusta e capacidades avançadas de processamento de dados.
A detecção de deriva de modelo e dados é outro desafio significativo. Identificar quando um modelo está se tornando menos eficaz devido a mudanças nos dados subjacentes requer um monitoramento sofisticado e ferramentas analíticas.
Um equilíbrio delicado deve ser mantido entre evitar alertas falsos e manter a sensibilidade necessária para detectar problemas reais. Excesso de alertas pode levar a “fadiga de alerta”, enquanto sensibilidade insuficiente pode resultar em problemas não detectados.
Determinar e monitorar as métricas corretas é fundamental para um monitoramento eficaz. Isso inclui métricas como precisão, recall, e F1-score para classificação, além de métricas específicas do domínio de aplicação.
Desenvolver um protocolo de resposta rápida para alertas de desempenho é essencial. Isso pode incluir procedimentos de re-treinamento automático ou ajustes manuais do modelo.
Para superar desafios de integração e escalabilidade, estratégias de implantação adaptativas, como a implantação canary ou blue-green, podem ser utilizadas. Além disso, a adoção de contêineres e microserviços pode facilitar a escalabilidade e a manutenção.
Para o monitoramento eficaz, ferramentas avançadas que utilizam técnicas de inteligência artificial para detectar padrões anômalos podem ser empregadas. Estas ferramentas podem ajudar a identificar rapidamente a deriva de dados e ajustar os modelos conforme necessário.
Monitorar continuamente os modelos de Machine Learning não é apenas uma prática operacional, é uma estratégia crítica para garantir que as soluções continuem a agregar valor e se adaptem às mudanças do ambiente. As ferramentas e técnicas de monitoramento, juntamente com uma abordagem proativa e adaptativa, são essenciais para alcançar esse objetivo.
Superar os desafios na implantação e monitoramento de modelos de Machine Learning é fundamental para o sucesso das operações de MLOps. Esses desafios requerem uma abordagem cuidadosa, que equilibra a inovação técnica com as necessidades práticas do negócio.
Considerações Finais: O Futuro das Arquiteturas de Software em MLOps
Ao concluir o artigo “Machine Learning Operations (MLOps): Um Guia para a Construção de Arquiteturas de Software Otimizadas”, é imperativo revisitar os conceitos chave e lições aprendidas ao longo desta jornada intelectual. Esta seção final tem como objetivo sintetizar os tópicos abordados, refletindo sobre as implicações práticas e teóricas dessas discussões e delineando caminhos futuros para pesquisa e aplicação.
Recapitulando tudo o que apresentamos aqui, discutimos como o MLOps serve como uma ponte crucial entre o desenvolvimento de modelos de Machine Learning e operações eficientes em ambientes de negócios, ressaltando a importância de estratégias de implantação eficientes e monitoramento contínuo para garantir a eficácia e relevância dos modelos de Machine Learning.
Abordamos os desafios enfrentados nas operações de MLOps, como integração com sistemas existentes, escalabilidade, gerenciamento de recursos e questões éticas. Enfatizamos estratégias inovadoras que incluem automatização avançada, orquestração de workflows e uso de ferramentas de monitoramento sofisticadas.
Reconhecemos que o MLOps não é apenas uma tendência tecnológica, mas um movimento transformador que está redefinindo como as organizações desenvolvem, implantam e gerenciam aplicações de Machine Learning. As lições aprendidas destacam a importância de uma abordagem holística e adaptativa para enfrentar desafios técnicos e operacionais.
O futuro do MLOps promete exploração contínua de novas fronteiras tecnológicas, como a incorporação de IA explicável, a integração de edge computing e a adoção de práticas sustentáveis e éticas no desenvolvimento de Machine Learning.
Referências para Pesquisa Futura
Para continuar a exploração e aprofundamento nos temas de MLOps, recomenda-se:
- S. Amershi et al., “Software Engineering for Machine Learning: A Case Study,” 2019 IEEE/ACM 41st International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP), Montreal, QC, Canada, 2019, pp. 291-300, doi: 10.1109/ICSE-SEIP.2019.00042.
- Denis Baylor, Eric Breck, Heng-Tze Cheng, Noah Fiedel, Chuan Yu Foo, Zakaria Haque, Salem Haykal, Mustafa Ispir, Vihan Jain, Levent Koc, Chiu Yuen Koo, Lukasz Lew, Clemens Mewald, Akshay Naresh Modi, Neoklis Polyzotis, Sukriti Ramesh, Sudip Roy, Steven Euijong Whang, Martin Wicke, Jarek Wilkiewicz, Xin Zhang, and Martin Zinkevich. 2017. TFX: A TensorFlow-Based Production-Scale Machine Learning Platform. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD ‘17). Association for Computing Machinery, New York, NY, USA, 1387–1395.
- Kuangyi Gu. 2022. Deep Learning Techniques in Financial Fraud Detection. In Proceedings of the 7th International Conference on Cyber Security and Information Engineering (ICCSIE ‘22). Association for Computing Machinery, New York, NY, USA, 282–286.
- Patricia Craja, Alisa Kim, Stefan Lessmann. Deep learning for detecting financial statement fraud. Decision Support Systems, Volume 139, 2020, 113421, ISSN 0167-9236.
- Vinay Sridhar, Sriram Subramanian, Dulcardo Arteaga, Swaminathan Sundararaman, Drew Roselli, and Nisha Talagala. 2018. Model governance: reducing the anarchy of production ML. In Proceedings of the 2018 USENIX Conference on Usenix Annual Technical Conference (USENIX ATC ‘18). USENIX Association, USA, 351–357.
- J. M. Kanter and K. Veeramachaneni, “Deep feature synthesis: Towards automating data science endeavors,” 2015 IEEE International Conference on Data Science and Advanced Analytics (DSAA), Paris, France, 2015, pp. 1-10, doi: 10.1109/DSAA.2015.7344858.
- Mahmood, Rafid & Lucas, James & Alvarez, Jose M. & Fidler, Sanja & Law, Marc. (2022). Optimizing Data Collection for Machine Learning.
- Margaret Mitchell, Simone Wu, Andrew Zaldivar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, and Timnit Gebru. 2019. Model Cards for Model Reporting. In Proceedings of the Conference on Fairness, Accountability, and Transparency (FAT* ‘19). Association for Computing Machinery, New York, NY, USA, 220–229.
- Andrei Paleyes, Raoul-Gabriel Urma, and Neil D. Lawrence. 2022. Challenges in Deploying Machine Learning: A Survey of Case Studies. ACM Comput. Surv. 55, 6, Article 114 (June 2023), 29 pages.
- D. Sculley, Gary Holt, Daniel Golovin, Eugene Davydov, Todd Phillips, Dietmar Ebner, Vinay Chaudhary, Michael Young, Jean-Francois Crespo, and Dan Dennison. 2015. Hidden technical debt in Machine learning systems. In Proceedings of the 28th International Conference on Neural Information Processing Systems - Volume 2 (NIPS’15). MIT Press, Cambridge, MA, USA, 2503–2511.
- MD. Zakir Hossain, Ferdous Sohel, Mohd Fairuz Shiratuddin, and Hamid Laga. 2019. A Comprehensive Survey of Deep Learning for Image Captioning. ACM Comput. Surv. 51, 6, Article 118 (November 2019), 36 pages.
- Eberhard Hechler , Martin Oberhofer , Thomas Schaeck. Deploying AI in the Enterprise: IT Approaches for Design, DevOps, Governance, Change Management, Blockchain, and Quantum Computing. (2020), Apress Berkeley, CA. 978-1-4842-6206-1, Published: 25 September 2020.
- Emmanuel Ameisen. Building Machine Learning Powered Applications. Released January 2020. Publisher(s): O’Reilly Media, Inc. ISBN: 9781492045113.
- Mark Treveil, Nicolas Omont, Clément Stenac, Kenji Lefevre, Du Phan, Joachim Zentici, Adrien Lavoillotte, Makoto Miyazaki, Lynn Heidmann. Introducing MLOps. Released November 2020.Publisher(s): O’Reilly Media, Inc. ISBN: 9781492083290
- “Effective DevOps with AWS“ por Nathaniel Felsen (O’Reilly, 2018).
- “Machine Learning Yearning“ por Andrew Ng – Um guia prático para o desenvolvimento de modelos de ML, com ênfase na transição para a produção.
- “Monitoring Machine Learning Models in Production” por Christopher Samiullah (2020) - Um guia sobre como manter a eficácia dos modelos de ML ao longo do tempo.
- Deploying AI in the Enterprise” por Eberhard Hechler et al. (Springer, 2020) - Discute estratégias para a implantação eficaz de modelos de ML em ambientes corporativos.
Leave a Comment